





标题:揭秘大数据实时计算开源系统:架构、优势与挑战
引言
随着互联网的飞速发展,大数据已经成为各行各业不可或缺的一部分。实时计算作为大数据处理的重要环节,能够帮助企业和组织快速响应市场变化,做出实时决策。本文将深入探讨大数据实时计算开源系统,分析其架构、优势以及面临的挑战。
大数据实时计算开源系统概述
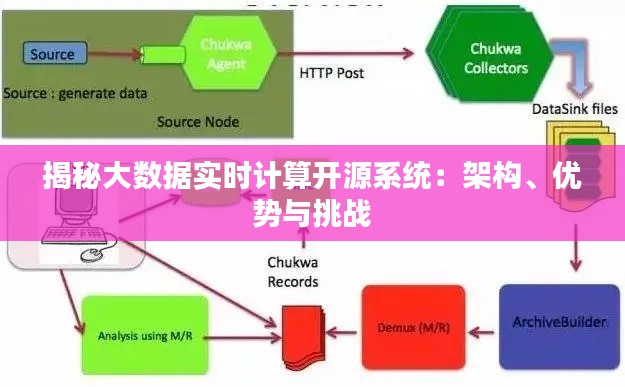
大数据实时计算开源系统是指基于开源协议,由社区共同维护和发展的实时数据处理平台。这些系统通常具有高并发、可扩展、易维护等特点,能够满足大规模实时数据处理的需求。目前,市场上较为知名的大数据实时计算开源系统有Apache Flink、Apache Spark Streaming、Apache Storm等。
架构解析
大数据实时计算开源系统通常采用分布式计算架构,以下是几种常见架构的解析:
1. 拉模型(Pull Model)
拉模型是一种基于消息队列的架构,数据源通过消息队列将数据推送到消费者。消费者从消息队列中拉取数据,进行处理。这种架构具有较好的可扩展性和高可用性,但消息队列的延迟可能会影响实时性。
2. 推模型(Push Model)
推模型是一种基于数据源主动推送数据的架构。数据源将数据推送到消费者,消费者被动接收数据。这种架构的实时性较好,但可扩展性和高可用性相对较差。
3. 混合模型(Hybrid Model)
混合模型结合了拉模型和推模型的优点,既能保证实时性,又能提高可扩展性和高可用性。在实际应用中,可以根据具体需求选择合适的模型。
优势分析
大数据实时计算开源系统具有以下优势:
1. 开源协议
开源协议使得用户可以自由使用、修改和分发系统,降低了使用成本。
2. 社区支持
开源项目通常拥有庞大的社区,用户可以从中获取技术支持、交流经验和获取最新动态。
3. 高性能
大数据实时计算开源系统经过优化,能够满足大规模实时数据处理的需求。
4. 易于扩展
分布式计算架构使得系统可水平扩展,提高处理能力。
5. 易于维护
开源项目通常具有良好的文档和社区支持,便于用户维护。
挑战与展望
尽管大数据实时计算开源系统具有诸多优势,但在实际应用中仍面临以下挑战:
1. 系统复杂性
大数据实时计算开源系统涉及众多组件和技术,对于开发者来说,学习和维护具有一定的难度。
2. 性能瓶颈
随着数据量的不断增长,系统性能可能会出现瓶颈,需要不断优化和升级。
3. 安全性问题
开源系统可能存在安全漏洞,需要用户关注并及时修复。
4. 生态圈建设
开源项目需要建立一个完善的生态圈,包括工具、文档、培训等,以提高用户的使用体验。
未来,随着技术的不断发展,大数据实时计算开源系统将在以下方面取得突破:
1. 性能优化
通过算法优化、硬件升级等方式,提高系统性能。
2. 安全保障
加强系统安全性,降低安全风险。
3. 生态圈完善
建立完善的生态圈,为用户提供更好的使用体验。
4. 跨平台支持
支持更多平台和设备,提高系统的适用性。
总结,大数据实时计算开源系统在当今大数据时代具有重要作用。了解其架构、优势、挑战以及未来发展趋势,有助于用户更好地选择和使用这些系统,为企业和组织创造更多价值。
转载请注明来自云南良咚薯业有限公司,本文标题:《揭秘大数据实时计算开源系统:架构、优势与挑战》






 滇ICP备2021007469号-1
滇ICP备2021007469号-1